An update on GitHub availability
52 points by martinald
52 points by martinald
It's telling that there are multiple footnotes along the lines of, "No, not that outage, the other ones."
Lately, I've been very publicly critical of GitHub. [...] It is irrationally personal. I love GitHub more than a person should love a thing, and I'm mad at it. I'm sorry about the hurt feelings to the people working on it.
I am really digging how emotionally aware he's being, and how much he cares about GitHub and the people who work there. Kudos to you, good sir.
I wouldn't buy anything they are saying. I think they've found a convenient data point with the growth numbers to latch on to and they're now using it as an excuse for their entire reliability situation.
I remember this one: https://x.com/can/status/2047823390342324572
maybe im bitter because this bit me but the COO of going out of their way to find a huge denominator to make the impact appear small makes feels very dishonest versus a sincere apology about how this invalidates their entire promise to their customers. we had to dig into their status page about this to even realize they just casually fucked up our repo
Repositories are entirely independent so their operation should scale horizontally without this much issue. If anything, this is a huge indictment of Azure as a cloud solution.
I do find myself wondering if the move to Azure was something that GitHub infrastructure people actively wanted, or if it was a top down mandate from Microsoft. Top down mandate for an unwanted migration is the kind of thing you can't publicly blame for these sorts of problems.
Top down. I was on the product side of things, so not as close to this decision, but all the friends I had on the infrastructure side of things just would tell me how they were being told to move and yet the capacity necessary did not exist.
Indeed, far from blaming it, they are praising it:
We also leveraged our migration to Azure to stand up a lot more compute.
The awkward way that sentence is bolted onto the end of the paragraph reads to me like management edits.
fastherthanlime's video on Actions reminds us that they had demo'd a full automation system on github infra using HCL (the UI looks quite finished!). Microsoft bought them and "Actions" became a fork of Azure Pipelines. Sounds like a top-down mandate to me.
I thought I’d imagined that TBH, I remember looking at the documentation and being excited that HcL was chosen
The article almost suggests Azure was a mistake:
While we were already in progress of migrating out of our smaller custom data centers into public cloud, we started working on path to multi cloud.
Right - the migration to multi cloud jumped out to me as an admission that Azure is a failure.
And is an interesting choice. Multi cloud is hard compared to multi region which is hard compared to multi AZ. It's the kind of complexity which brings its own reliability issues.
I don't think that makes a difference. They're not going to publicly blame Azure even if moving to it started as a bottom-up initiative.
Repositories are entirely independent so their operation should scale horizontally
git operations could technically scale horizontally (not for very active large monorepo) but the metadata (authz) and cross repository workflow (PR merge) will start causing problems.
Service serving the repository could very well suffer from noisy neighbor problems. Having well defined QoS and throttling requires end to end request tagging going all the way to filesystem IO. Not sure how deep GH request tagging is and how sophisticated their rate limiting is. These are real technical challenges that are hard to do at scale and on the cloud.
Disclaimer: I work at another forge and am trying to solve the very same issues.
Repositories are entirely independent so their operation should scale horizontally without this much issue
when designed from first principles a lot of things "should" be the case. I wouldn't be so quick to blame azure for this one.
I know the author explicitly lists it as "strongly discouraged," but BitBucket has got to be hands down one of the worst websites (let alone Git forges) I've ever used... even if GitHub got substantially worse then it already is, convincing me to use BitBucket would be a tall order.
BitBucket gives you the ability to generate a token and use that token to write or read your repository.
These tokens can have an expiry date. Great!
But the only way to regen the token is to log in to the website and click a button.
API for that critical feature is a work in progress.
SSH keys for the same purpose can only be used to read the repo not write to it.
My conclusion is harsh and not fully defensible, but in my mind, Bitbucket is not serious software ready for even basic non-LLM pro-security automation.
(author here) yeah agreed, Bitbucket website truly is an awful experience lol (my thoughts)
If willing to bounce from MS-owned GitHub, why be limited to Git? 🤔 There’s an even bigger ocean of options to see.
It's terrible! yet, somehow it supports threaded replies in PR discussions, which is super useful
I took a job at a company that uses BitBucket and I can’t believe how bad it is.
So I started moving the repos to GitHub … and I can’t believe how bad it’s become.
So I decided we should self host forgejo but I’ve been put off by the backup story and the recent security issues reported here.
So now I’m stuck. But god I love self hosting Woodpecker CI, despite some irritations.
Author also left a heartfelt comment on HN.
Interesting that he recognizes his attachment as unhealthy in the comment but not the blog. The replies tho, my god.
Just coincidence, I wrote the blog a couple weeks ago and didn't use that word. I used the word "irrational" instead, but I'd say its both irrational AND unhealthy. :)
Nobody should cry over a SaaS, of all things. But GitHub has meant so much more to me than that (all laid out in the post).
There are some things in life that do not make sense to cry about, and yet they have had such an impact on us that the tears flow nevertheless.
Emotions tell us important things about ourselves. I don't think it's ever really correct to say that something doesn't make sense to cry about. Emotions are real but are not always an accurate reflection of reaility. Understanding that is I think key to being healthy.
You should never be a slave to your emotions, but you should absolutely be aware of them and how and why they affect you.
Absolutely and I think GitHub, certainly if you have been there so early, can be one of those things. For many things GitHub is the platform they first hosted their projects one, that supported an entire generation of open source software and a whole lot more.
But in general I think we tend to give less credit to the impact digital spaces have on people compared to physical spaces. They are still spaces where people spend time, find community, etc. I think it is only logical to have some sort of emotional response when seeing those spaces change, certainly degrade.
But I also know what you mean. Especially for people who remember early GitHub, it was a website built with real heart. So much of it was a joy to use. And like Mitchell, a large chunk of my career was lived on that website.
I’ve been feeling similarly wrt my relationship with github, I’m quite saddened by their priorities. It has been my number one site for the last decade, and I’ve been reading through as many github repos as I could the entire time, enough to build supporting tooling to view all of my bookmarks (because the stars feature has been underdeveloped on github forever).
GitHub Actions became so unbearable we were forced to move off, because with 50+ jobs running on each commit we were almost guaranteed some transient error in at least one. I thought I was going insane this morning when I couldn’t find a PR I was certain I had opened, and once I saw a second specific PR not appear I knew something was up.
Mitchell’s take that they should shutdown Copilot and focus on their actual product is the parallel universe I dream of at night. I do not want ads in my code view or achievements or a 5th new “dashboard”, I need my critical infrastructure to WORK. The fact that the code review UI got a refresh while practically looking the same with still bad performance is a testament that they need to reevaluate things. Personally I don’t want to review as many 1000+ file PRs as I do, but the fact that the bottleneck isn’t my eyeballs is insane.
Shutting down Copilot sounds like a good idea. Buying Pierre is a bit of an odd choice considering they haven't really accomplished anything that would be worth acquiring, at least that I know of.
I doubt this will ever happen though. Such projects require the whole organization to agree and work towards the goal and I just don't see that happening at GitHub/Microsoft.
I'd also suggest people consider self hosting or using other providers. Codeberg is great, but moving from one monoculture to another isn't.
I definitely cringed when Zig moved to Codeberg!
imagine people having standards! how cringe! it's not as if they were correct about GitHub's trajectory, right?
also vaguely humorous to me that zig is small potatoes, but ghostty is hot shit… i wonder what ghostty is implemented in
An emotional reaction is an emotional reaction. Codeberg in the current form is unfortunately quite unreliable and the user experience is not great at all. I think it's great that a large project moves, and I think I acknowledged this plenty in the post.
An emotional reaction is an emotional reaction.
Valid.
Codeberg in the current form is unfortunately quite unreliable ...
I think it has more nines than Github.
and the user experience is not great at all.
Subjective, but, I take the point. I don't use it myself (I use Gerrit & Gitlab) but from clicking around I don't see major regressions when compared to Github, do you have specific complaints? Maybe that's a more constructive method in order to enact the change you wish to see.
One thing I've found myself missing a ton when looking at projects on Codeberg is code search. I know why this isn't offered, but it's annoying when I just want to find where a specific function is defined in a repository. Basically the only reason I look at random repositories is to look at code, so this is extremely unpleasant.
Another thing that's bothered me in my little time using it is the interstitial redirects. I get why these too are necessary, but it's just another small cut against usability. Of course, I don't have an account so maybe the both things go away then?
Why isnt't it offered?
Well to be clear this is all speculation but:
There's probably also more implementation issues, e.g. https://github.blog/engineering/architecture-optimization/the-technology-behind-githubs-new-code-search/ says GitHub had to implement their own rather than using zoekt. It sounds like they replaced trigrams with some weird version, for example.
It turns out I was overthinking this, they have https://codeberg.org/Codeberg/Contributing/issues/26 open but nobody's done anything. I don't get why they keep talking about opensearch/zincsearch there though, given those don't allow regex searches!
However, parts of the UI that depended on search showed no results, which caused a significant disruption.
This is one of the systems we had not yet fully isolated to eliminate as a single point of failure
It rather seems to me they did isolate the failure (search being down didn't take down the entire website), but in a really sloppy way, because instead of throwing a 500 or making a specific React component not load, it just silently returned wrong results. API calls were the same, we had actions that failed with really cryptic errors because some resource "disappeared." I can't imagine what happens to all those self-driving agents people use, and what they might have concluded from random resources disappearing. Would they try to "restore" them?
Note that nothing about this has anything to do with scale and capacity, so I think blaming growth for all of this is wrong. At least in the way they do.
Somebody on Twitter jokingly said that "Codeberg now feels more reliable" without meaning it, but I actually agree with this. The uptime, as a number, is strictly worse, but all the failure modes that I've seen exist on a spectrum of loads --> loads slowly --> doesn't load. Codeberg is no fun to use and its default color scheme is grotesque IMO, but its behavior is more predictable, so I trust it more than GitHub at this point.
Imagine Codeberg has the kind of success that requires it to navigate a similar distributed systems scaling journey to GitHub's. We'll get a fully transparent open source record of every architectural adjustment, clever hack, lesson learned, all as part of the public commons.
And hopefully in the future as Codeberg hits more scaling problems, they can focus more on solving the problem by not using Codeberg! They already do a great job with Forgejo at making it easy to stand up your own instance (other than the federated login stuff being a bit of a pain) but what I'd love to see from them in the future is advice about how to start a Codeberg-like governance system. We shouldn't be putting all our eggs in one basket even if it's a pretty great basket.
(other than the federated login stuff being a bit of a pain)
Could you elaborate on this? It's unclear to me whether Forgejo has federated login support at all. There's quite a few updates posts and timelines saying it's just around the corner, but they're all from 2023, and progress seems to have stalled since then -- I see a little bit of spec work in the ForgeFed repository 10 months ago, but no notes on Forgejo's side on federated pull requests beyond it being "one of the final steps".
I'd love to be able to send a PR to somebody's personal Forgejo instance from Codeberg, or even have some OAuth system that lets me log into other Forgejo instances from my main Codeberg account... but it's been my impression that both of these are technically far, far, far away.
If you've got some kind of nice federated login system I'd love to hear about it.
The current setup with OAuth is that the admin of each individual forgejo has to go make an account on every single other forgejo that they want their users to be able to log in with, and manually register a client there with each of them. This means that you can't go up to forgejo and enter the name of your own forgejo server like you should be able to, because forgejo doesn't support dynamic client registration.
If you allow for dynamic client registration, you can do this easily. I've implemented it with about 100 lines of code both in Trac (https://dev.fennel-lang.org) and in my own Fennel web app (https://fedibot.club). I hope that Forgejo can support this flow too at some point!
The main downside of what I've implemented is that it relies on a de-facto standard Mastodon API rather than a real standard. There's a standardization effort going on for dynamic client registration, but it's still in progress. Hopefully that's the reason Forgejo hasn't implemented this yet; because they are waiting for the standard to land and don't want to tie themselves to this ad-hoc nonstandard flow? But I'm just speculating.
I honestly think the login stuff is where 90% of the benefit is and the rest of ForgeFed is just not that interesting to me in comparison.
Hopefully that's the reason Forgejo hasn't implemented this yet; because they are waiting for the standard to land and don't want to tie themselves to this ad-hoc nonstandard flow? But I'm just speculating.
Sadly, this isn't the case. The efforts on federation in Forgejo are effectively entirely restricted to writing blog posts about how they will be federated. This is something they haven't bothered to achieve over the last 2-3 years.
I wish more people would use such reasoning as part of their tech choices. The world would look very different indeed!
availability concerns aside, do you find GitHub to be particularly fun to use?
Yes, compared to codeberg. Off the top of my head:
L to assign labels.GitHub’s attempt to avoid page reloads with js navigation is so unreliable it fails for me every time I try to browse a repository. To avoid the broken back button I have to open links in new tab and close the tab to go back. Very tiresome.
Codeberg’s full page loads are much faster than GitHub’s js jank and because it doesn’t override basic browser functionality I know it will work properly.
Oh my god this is so god damn annoying. I am on a page. I click a link. The browser navigates to the linked page. I click the back button. Nothing happens. I click the back button again. I end up on wherever I was before GitHub.
It used to just work.
I see that too. In particular I'm suffering from a bug where the page title doesn't update, so all my tabs are named wrong. Somehow, it's still a better experience than on Codeberg. Whether Codeberg loads any faster really depends on the time of day.
Codeberg doesn't auto-refresh anything except CI status. It annoys me on issue and PR conversations.
GitHub's auto-refresh, however, has led to an inconsistent state on more than one occasion for me, hiding comments until a full page refresh or showing my own commits twice. I would prefer consistent no-auto-refresh over auto-refresh-but-might-be-wrong.
What I've seen is that you're viewing a pull request, the bar at the top says you have 4 open pull requests, you click the "merge pull request" button, the javascript thinks for a bit and then eventually shows the pull request as merged, but the bar still says you have 4 open pull requests. You have to do a full page reload for the 4 to change to 3.
Would've been a better user experience if the "merge pull request" button was just an old school form submission which caused a full page refresh.
Right, but: It's not all-or-nothing. GitHub 7 years ago had it figured out. I think Codeberg sometimes steers too far away from improving UX just to avoid possible bugs.
GitHub has significantly more keyboard shortcuts, particularly around issue management. I always get disappointed on Codeberg trying to hit L to assign labels.
FYI I've quoted this over at https://codeberg.org/forgejo/forgejo/issues/7818#issuecomment-13941926. I want more of this stuff too. The Forgejo crew love to build a clear picture of what users actually want before diving into code, and comments like yours here are a big help in getting closer to consensus about what's needed. Specifically mentioning L was especially helpful in this case.
I've read the forgejo issue tracker in the past and my impression is that there's primarily a resourcing problem, and not enough people just using GitHub to form their own opinions, then also driving work on Forgejo based off that. There is just a lot of talk, with users on one end and developers on the other.
Codeberg is simpler enough to not have the following issues:
GH is failing on the complexity they introduced. Codeberg doesn't have that complexity (yet)
For people moving to codeberg, if you can at all, you should donate: https://donate.codeberg.org/
I started by making an account, will kick the tires porting some projects. It sure would be great if they also supported private projects out of the box. Like, take my money!
but mind they are not a business like https://git.sr.ht/ but a non-profit and don't promise five nines. I support them both since I moved there https://blog.mro.name/2024/10/scaling-infrastructure/#github-com
Yes, to both of them.
Thank you, SourceHut has visibly improved since I last checked it out years ago. The CI stuff is particularly interesting, as I rely a lot on github actions.
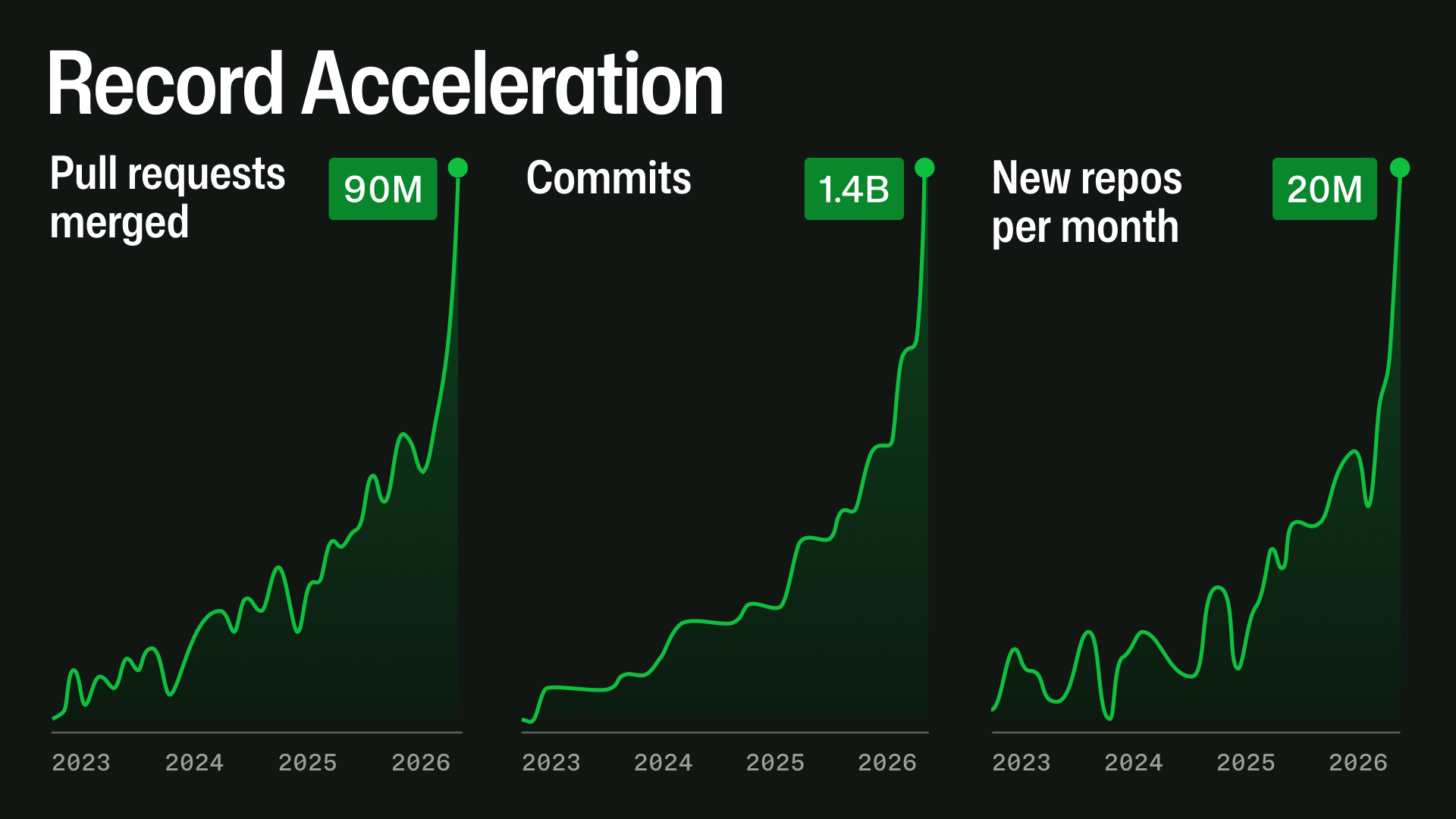
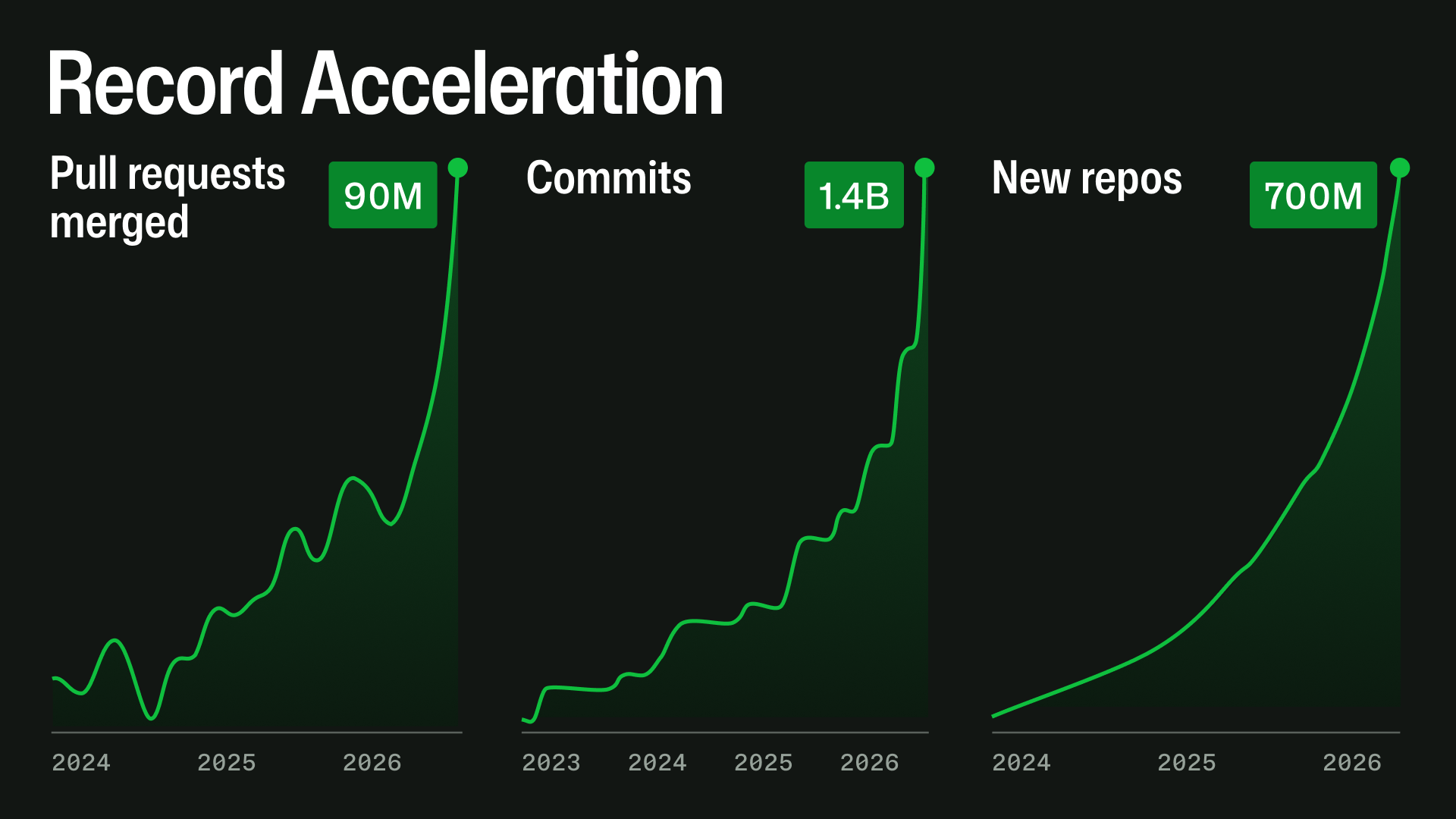
The graph they include to illustrate demand growth doesn't include the y-axis :(
Link to photo: https://github.blog/wp-content/uploads/2026/04/record-accelleration-1920x1080-2.png
If you change that 2 to 1, I assume you get the previous version of the same image.
It is a bit different, like the number in the first version was 700M new repos per month but was changed to 20M.
https://github.blog/wp-content/uploads/2026/04/record-accelleration-1920x1080-1.png
Still no y-axis though
The older image’s rightmost graph says 700M “new repos” (cumulative), which explains why the number is different from the newer graph’s 20M “new repos per month”.
All that chart tells me is that GitHub is too centralized and we should be trying to lean more into decentralization. We should have known since the beginning, but everyone has to learn some lessons the hard way.
I was a Trac user back in the day too, before switching to git. They lost nearly all their userbase when they took a long time to add git support, but they did eventually add it! I recently switched my biggest project back to Trac, and it's worked great for the most part: https://dev.fennel-lang.org
There were a few weird hoops I had to jump thru around adding support for Markdown and federated login, but they were surprisingly easy to address. I blogged about it at https://technomancy.us/204
I think this is the best themed Trac I've seen, was certainly not expecting it to actually be mobile-friendly and not overflow the page edges everywhere.
I switched from Trac to GitHub because of spam. The only way to deal with it at the time was to require user accounts, but then people wouldn't bother register on each Trac instance in the wild. OpenID was a thing back then, but it was not that straightforward for people to setup one.
The fennel link above allows me to login with github (worked perfectly) and fediverse accounts (which I didn't try). The fediverse login has me excited, is seems this was done by technomancy themselves
Tangled seems like an interesting alternative build on top of at protocol. The atmosphere ecosystem becomes more and more federated every day. I think it has a huge potential.
I've been interested and also slightly confused by tangled. I don't really understand what atproto has to do with "being a place to host git repos" or why that is a feature.
The biggest problem with self-hosted forges is that you need to authenticate separately for each instance. With tangled/atproto, you share the login details and your metadata is all easily accessible, but you can choose where the git hosting goes.
Here are all my personal browsable tangled records, for example: https://pdsls.dev/at://did:plc:nhyitepp3u4u6fcfboegzcjw#collections:sh.tangled
Despite the metadata being public, I run multiple git servers (for my personal use, for my research group) and those are sitting on our own self hosted infrastructure. If there's ever an internet outage, git pull/push still works fine locally. I like it.
i wrote a bit more about that in a recent comment: https://lobste.rs/s/y8jlwv/tangled_newsletter_01_hello#c_wmdomg
Basically atproto offers a universal identity to reuse in various apps (bluesky, weareonhire and margin) and federated storage of user choice which guarantees some better client could be built on top of the same data if Tangled itself won't cut it.
It's such a pity they decided to use Atproto instead of more open-protocols or existing efforts. Atproto is developed by Bluesky which is a for-profit corporate.
AT Protocol is an open protocol, and is being standardized at the IETF now. Regardless of whether Bluesky pioneered it, it's just a spec. We chose it because it fits our paradigms very well—ActivityPub (ForgeFed) hasn't progressed at all, and nostr/Radicle aren't great at UX (although I'm sure Radicle will solve this!).
Ultimately, we don't rely on Bluesky for anything, we host our own infrastructure and are well capable of advancing the protocol on our own should that be required.
Appreciate the clarification, I had the wrong impression ATproto and the ecosystem was still largely driven by VC backed companies.
Ironically though it's looking like ATproto may actually be better suited for hosting services like tangled than it is for Bluesky, which from a decentralization PoV seems very much like a dead duck.
I totally agree; ATProto is a much better fit for git hosting (Tangled), long form publishing (standard.site) and other 'heavier' services than microblogging where choose the location of your data actually matters (I don't really care where the media behind my random Bluesky posts are stored, but I really do care where my Git repositories are since there's gigabytes of important content in there).
Nonetheless the ecosystem is growing and a lot of infrastructure tooling is built outside of bluesky. For profit doesn't always mean bad, this is usually where most funding is coming from.
I understand. This is definitely my personal reaction to be wary of VC driven software who get funding from crypto companies vs. W3C working group led standards.
This is about the third or fourth post I've read today about moving away from GitHub. Partially because I've searched for this kind of posts.
I also want to leave GitHub but there a two which hinder me currently:
I've moved two medium-to-big projects off GitHub to a self-hosted Forgejo recently, and have not noticed a drop in issues or PRs. People seem fine with the two clicks it takes to create an account via GitHub (or Codeberg) OAuth. The interface is familiar enough.
Gitlab used to drive me dotty because it wasn't close enough to gh for my muscle memory to work (I don't cope with change well.) Forgejo it turns out is close enough, and is actually way more responsible on my low-end hardware.
Consider Sourcehut? I've been using their CI runners for a few small projects and they've been great. I particularly like that they're designed to be debuggable; if a build fails they give you SSH access to the agent for a while.
Yeah, my main issue with leaving GitHub is also losing visibility and drive-by contributions. There's technically nothing stopping me or you from just hosting mirrors on multiple platforms and accepting contributions from any of the platforms while still relying on the infrastructure from one of them mostly, but it is more work and slightly less convenient.
If enough people jumped ship or had their projects elsewhere, I would also jump ship instantly. I don't really mind going into multiple websites to contribute to different projects. I don't even understand how GitHub managed to tie us down like this because by the time I became a developer GitHub already had everything locked into their walled garden.
A read-only mirror on gh should be enough for visibility at least (depressingly, if I want to search for open source projects that perform a particular role, I often have the most success adding "github" to my google/kagi search terms.) PRs .. some bigger projects seem to now be getting overwhelmed with AI generated stuff; adding a bit of friction might actually be good future proofing?
I don’t have any time to write but I’ve been using woodpecker CI at $WORK and managed to get my CI builds done under a minute. It’s incredible how much more you can do when you own the infra. Even if it’s running on a VM.
I get an LLM to transform from my old CI to Woodpecker and it’s pretty good.
I am coming from Bitbucket but I’ve used Github actions a lot in the past and I just can’t believe how much easier it is to do it yourself.
I’m gonna look at self hosted forgejo next. I’ve been emboldened.
Yeah, losing actions as someone who only needed to use them occasionally and doesn't have a lot of experience with CI/CD setup is a pain. Codeberg is definitely a lot more limited at the moment, but hopefully that can change in the future (or other services will step up).
I'm kinda glad I never looked at the achievements on my own account, didn't get attached to begin with. I still have to use GitHub to contribute to existing projects, but anything new I start will be elsewhere.
I've also been having the same kind of thoughts with regards to Anubis. I'm not sure where to go though.
The main driver is a rapid change in how software is being built. Since the second half of December 2025, agentic development workflows have accelerated sharply. By nearly every measure, the direction is already clear: repository creation, pull request activity, API usage, automation, and large-repository workloads are all growing quickly.
It's obvious that this isn't sustainable. Brace for impact. In my opinion, there are only two ways forward: The service becomes more unstable or some value has to be extracted from the users to pay for this capacity. It is likely that alternatives will become much more attractive in the near future.
some value has to be extracted from the users to pay for this capacity
I mean, don't get me wrong, this is absolutely happening already and going to accelerate in the future, but the idea that more money would solve these problems? I don't see any evidence of that. They are very far from being resource-constrained.
They are very far from being resource-constrained.
Every system is resource-constrained, all the time. It may not be clear to everyone what resources are constrained and how, but they are certainly there. When an organization behaves seemingly nonsensically, one of the common reasons is a constrained resources that people outside don't see.
Right; I should have said cashflow-constrained rather than resource-constrained; that's fair.
Whether GitHub's stated claim that this is because of the quantity of use going up is true or not, it is a very interesting discussion point.
Any online service that allows user-generated content should probably be bracing for impact now if they aren't already for dealing with a tsunami of AI-generated stuff. That in turn means that value the service can generate (through ads, sales, whatever) per unit of stuff is probably going to go way down. Given how narrow those margins already are, I wonder how much the AI firehose is going to kill companies or force them to change their upload policies.
github is uncool? How can that be, with an owner renowned for coolness.
But seriously, the mass chooses convenience and wonder how they end up at mediocre monopolists. Everybody whining deserves no better but had to leave the comfort zone.
P.S.: there is no coolness in convenience.
there is no coolness in convenience
That should be a bumper sticker. It’s so true and so often ignored!
In fairness to the masses, convenience is the most effective selling point for hacking consumer brains, a key part in the enshittification toolchain and why we continue to get got by platforms and services that promise to make our lives easier or do less thinking. It's going to be exceptionally hard to break that cycle, even if we are hyper-aware of it. Our drive to make things easier for ourselves is one of the most exploitable flaws in the Human OS™.
i am mind still mindblown that many people in tech still use twitter. after all the shitshow it has been since elon musk took over, it shows how low the bar can be for some people. i can't imagine the same ones leaving github for simply offering subpar services.
Hmm... I wonder if there are any technological changes recently that may be influencing the release of low-quality code to production.
Snark aside, the growth in number of repositories does nothing to explain the regression in merge queues. Clearly these two issues are not connected, even if the regression has introduced to handle the higher load.
Either I ended up on some permanent untrusted list or GitHub did this to everyone and nobody else cares, but sometime in 2024 GitHub started severely rate limiting downloads and basically every open source project that relies on git cloning from GitHub or downloading from the GitHub container registry takes forever to install.
I wish more projects would self-host. At least then I could be surprised once in awhile at having some fast downloads!
Using a git forge as a free CDN puts a huge amount of load on the forge, especially if git clone is used to download the data. If more folks would self host then I don't believe it would be viable for projects to do this any more as the self-hosted forges would be not be able to keep up.
The responsible thing to do is to an actual CDN and not to make forges pay for your hosting costs.
I've always found "relying on git cloning other repos" especially distasteful . pkg-config was invented decades ago specifiically to be able to depend on library interfaces rather than specific instances of libraries.
What surprised me most about this article is how young the author is!
Whoops, another outage. https://githubstatus.com https://www.githubstatus.com/incidents/dbypmw7h77l5
Issues, reviews, design discussions, release notes, security advisories, and old tarballs are fragile.
I feel like most of it is a technical problem, first and foremost. If issues and code reviews were part of the git repo, archival, migration, and continuous inter-operation of various forges would have been much much easier. There are hard technical&UX problems to be solved there (how can you allow creating issues and PRs without commit access? How to model code review comments on changing code), but it feels like it should be surmountable. It also feels neglected. There are some developments, like git-bug, or gerrit using git notes for storage, but I haven't seen anyone trying to build an actual thing out of it, like we have with tangled, jj, codeberg, gitlab, sourcehut and the rest.
Moving issues&code review from forge into the repository, and CI out of the forge feel like $100 on the ground, wonder why no one seems to at least try to pick them?
I've been thinking, experimenting and building something (a forge!) on the side (mostly for my own personal satisfaction so far) that relies completely on the git itself as backend for code/issues/discussions/PRs/CI so I'd appreciate any kind of points and references that touches upon that (other than linked above).
The list of links at the end of TB blog post is all I have! You might also want to chat with @senekor (https://blog.buenzli.dev/announcing-development-on-flirt/). Oh, my version of CI part is here:
But the post by @indygreg is almost strictly superior.
Oh, while thinking about this today, I realized one more bit of information you'll want to store in git is "merge provenance" --- that a particular merge commit on main came from a particular PR, with a particular code review discussion, was approved by a specific committer, and vetted by specific CI run.
Flirt will have a backend that stores all code review information directly in the Git repository. However, the "archival" and "distributed social context" use cases aren't at the top of my priority list for why I'm doing it. So I suspect it won't be very good for that, at least at first.
I would prefer something with a simpler data model than git-bug. I like the idea of using a special branch to hold issues and merge requests, with a directory for each one containing a file per message, maildir-style. The messages can contain headers for authorship, in-reply-to threading, and metadata for things like changing the status or tags of the issue. Then on the side you can build an index to speed up common viewing and searching operations.
More speculatively, it would be neat if an MR directory could refer to successive versions of the work-in-progress branch, perhaps using a self-referential gitlink (repurposing a feature from the submodule machinery). Then it could do the job of my first-class cover letters idea, except that the directory contains the entire discussion.
Crazy idea, and likely it has obvious flaws, but... public-inbox?
You could have a branch with basically a mailing list, but likely build a decent bug tracker on top of that. (Debian's bug tracker is email, right?)
And likely you could build a web interface on top that does not look like a mailing list.
Yeah debbugs is part of the inspiration, and of course this thing would have a web-forge style UI and a command-line UI: although I want the raw data to be usable with little more than git and cat, it would need enough extra syntactic rules that it would be horrible to use without nice tooling.
(tho I don’t know what you are asking about “public-inbox”)
Wouldn't public-inbox give you a lot of what you need to implement that?
As I understand, it's a way to store a mailing list in a Git repository with the tools to insert new email there and ways to work with the mails inside.
Oh right, as in https://public-inbox.org/
I’m inclined to think that actual email is more likely to be a hindrance than a help, in particular attachments should be normal files in the repo not MIME encoded.
I haven’t looked at public-inbox in any detail but I get the impression it assumes a single writer. A git-based issue tracker needs to support multiple writers in a manner that allows conflict-free merges, so the data layout has to be designed with that in mind. And some careful thought needs to be given to spam and moderation, preferably so that it can be done early enough to prevent junk cluttering up the repo.
12-13 years ago I moved private repositories at my workplace from GitHub to a self-hosted GitLab instance. The reason for that was the poor uptime of GitHub and how disruptive it was whenever it was down. It's amazing that this still is a problem for them.
While everything worked on the self-hosted GitLab instance, we ended up having to migrate back to using GitHub, mainly due to pushback from developers that somehow couldn't adjust to buttons having slightly different names and locations...
mainly due to pushback from developers that somehow couldn't adjust to buttons having slightly different names and locations...
If you can hold on a little longer, I think the tide is turning. It's not such a niche thing any more.
On the other hand, while 12 years ago Gitlab was decent, today it's by far the worst Github alternative around; I'd imagine you'd get less pushback if you had your things on Forgejo or some other alternative.
On the other hand, while 12 years ago Gitlab was decent, today it's by far the worst Github alternative around
I'm a bit surprised to read this. 12 years ago GitLab was in 2014, at which stage GitLab was terrible in just about every sense: a terrible UI, terrible performance, bare-bones functionality, etc.
I'd say the best time for GitLab was some time between 2018 and 2022, in part because the massive amount of work that went into making it not go down all the time, to improve performance, etc.
My memory is a little different. I started using Gitlab in 2015. I distinctly remember trying it out in 2012 and it being unusable, partly because they refused to render the readme on the repository's splash page for some reason. By 2015 that problem had been fixed. It was still slow, but it worked pretty well other than that.
Over the next few years it was mostly fine, but from 2019-2022 there was a period where literally every time I logged in, I found a new bug I hadn't encountered before. Since 2022 I've mostly only used it as a backup mirror.
Couple of posts up about GitHub so figured I'd chime in. I'd like to keep adding more resources and examples as I encounter them (though plenty have come from this very site).
On the point of not self-hosting a forge: I configured iocaine recently, and the amount of poisoned URLs served is ridiculous. It's over 7.34 million URLs served over just over 3 days, or about 24 requests per second give or take if I'm reading the metrics right. Truly insane.
I was planning to handle this in my code forge by making hyperlinks into the code not have any href unless the user is logged in.
I figure it's the deep graph of public links, constantly updating, that draws bots like moths
I like that analogy. Limiting links would be an option, but it'd make casual browsing a bit more annoying for visitors that are passing by.
I suspect iocaine's infinite maze may be part on why there are so many requests indeed, as otherwise my static sites don't have that many URLs to crawl. So perhaps without iocaine they'd be done quick and leave me alone. But I'm undecided if letting them gather clean data through their abusive behavior is something I want.
Yeah it's tough, but I don't know how to deny the bots without making things harder for (some) real people at the same time.
Same boat. For my TypeScript packages, the blocker is trusted publishing: npm now supports GitHub, GitLab, and CircleCI, but not Codeberg/Forgejo, and JSR's OIDC flow is still GitHub-only. Until both registries support Codeberg as a trusted publisher, moving there would mean giving up the release setup I'm trying to keep.
It's quite ironic that npm only supports a handful of CI providers for their OIDC auth, given that the standard was created to provide a vendor-neutral way to authenticate. I guess it's partly because npm is owned by GitHub.
This post echoes a lot of my thoughts. I set up my own Forgejo instance for my blog because I did not want to flood Codeberg with images and such, causing the repo size take a lot of space.
I keep thinking about using sourcehut often, though. There is something very calm about it. I would need to learn the email based flow.
I know that the email based flow on sourcehut can be scary, but I've been using sourcehut for a few years without understanding it at all. Hasn't been a problem thus far.
I've been on sourcehut for a couple years now for private, non-collaborative projects and it's great. I love the calm UI.
I did not want to flood Codeberg with images and such, causing the repo size take a lot of space.
You should check out https://git-annex.branchable.com/! I stumbled upon it trying to solve this exact issue. It's been a while since I tried it out, and I'm still yet to use it "for real", but the rough idea is that the files you use annex for are tracked as symlinks to a special directory in .git, using the file's hash. It's a pretty elegant solution, imo.
I wonder what people think of sourcehut and tangled.org ?
I think these two are outliers in the current landscape of code forges and both take very interesting approaches: sourcehut is patch based and tangled is based on the interdiff workflow.
sourcehut: https://sr.ht/
I use and enjoy sourcehut. Only for solo projects so far, though. The UI suits me. The build service is dead simple. I like the way the secret handling works for that. Creating a new repository is just a command line push to a new remote. The server messages then give me a link to click to configure any other settings. The project feature lets you group arbitrary mailing lists, trackers and repositories together, which is nice when I want one tracker for three or four repositories.
There are lots of little touches like that which make it nice to use. I know the UI is not for everyone, but I very much like it. And I don't mind the lack of dopamine hits like stars and download counts and "fork" counts.
Ironically, I suspect that this paper by Microsoft may apply to the current situation with Github:
https://www.microsoft.com/en-us/research/wp-content/uploads/2017/06/paper-1.pdf
Consequently, increasing redundancy can counter-intuitively hurt availability because the more core switches there are, the more likely at least one of them will experience a gray failure. This is a classic case where considering gray failure forces us to re-evaluate the common wisdom of how to build highly available systems.
I don't know how reliable the data source for the uptime chart is since IIRC last time I got posted someone claimed that it probably just didn't have old data and is reporting it as green; I certainly don't think they had 100% uptime in 1996. But it definitely feels way worse recently.
As user 120,225 to join GitHub in 2009. I can assure you. It was not green all the time.
I think the difference is that the angry unicorn (if we ignore the first 1-3 years) usually only appeared for a couple minutes, and every couple of months - and then ssh push & pull still worked 50% of the time. Unless you were about to review some PRs it didn't really affect the work (just grab a coffee and it works again).
It's so long ago it's hard to remember clearly, but I do remember doing pushes to github repos and them failing for periods of time. But there was also probably a lot of growth in that period. From my ID to the ID of one of my reports (over 4 million) is only a gap of a few years.
Added below:
To be fair, a lot of sites were dealing with scaling issues at that time as well, they weren't alone in standing out as an outlier. We collectively put up with and normalized a lot more downtime in the 2000s than we realize I think. It was just part of working.
True, unless one of us kept track in detail.
But I am still 100% sure in the years where I actually used Github at work every day (interestingly that was only ~2011-2017, but my user id is <50k) that we never had some regular "every single day something is broken" unless it was this rare multi-day outage, but then it was fine again for many months
people start checking uptime stats when downtime becomes noticeable. GH felt much more reliable and faster a few years ago.
I agree we need a federation of forges of some kind. But I'm skeptical of using AT for this purpose. Maybe it's easier to self host the infrastructure for AT protocol for forges, but it's a pain for social media.
I'm not sure ActivityPub is the right answer either, but it seems to have more backing behind it already.
Been on the same journey re: GitHub -> Codeberg, and thinking of setting up a Forgejo instance for non-FOSS/personal projects. It's such a shame…2010s GitHub was a marvelous place, but, well, Microslop just couldn't help themselves. 🙄
A few things there sound like the complexity paradox - they tried to scale up in fancy ways and made the fixes themselves unreliable. Now they're trying multicloud as well which is going to be even more complicated.
I want to mention another solution like https://radicle.dev/
Radicle is an open source, peer-to-peer code collaboration stack built on Git. Unlike centralized code hosting platforms, there is no single entity controlling the network. Repositories are replicated across peers in a decentralized manner, and users are in full control of their data and workflow.
I think the comment of we (whoever we is) need an archive is really interesting. It probably extends to humanity needs a record of useful stuff but developers are likely to be the first to find a good solution. I wonder how much https://tangled.org/ fits the bill
unfortunately my post from yesterday seems to have been merged with github discussions, and didn't see much light, but we need to break free from monocultures and adopt a federation or forges: https://blog.tangled.org/federation/
18 years is a good run.
We have to deal with every service out there being gutted and sunsetted. It doesn't matter that much whether we like them or not. Being online has mostly been like swiddening, and probably will remain that way.
Not that I have any famous projects in GitHub... but I have been moving them to Codeberg. It also has a migration tool which makes it pretty easy.
I really wish the author had shared what he's moving to. I don't use github nearly as much as he does, so haven't been as affected by the recent outages, but I've been prevented from doing work because of github every day this week and a few days last week as well.
I don't really WANT to move, because as another commenter said, Github is where all the developers are, and also because I don't think there are any other good options. Gitlab is deeply uninspiring, Codeberg's "copyleft only" "no private repos" stance makes that not an option for me, I don't have the time, desire, or resources to self host forgejo.... So what's left?
Anyways I eagerly await the followup article where we learn where ghostty is moving to.
Hello , can you point me to a source ahobout Codeberg "copyleft only" stance? Looking at the FAQ, it says you must use a free and open-source license, and looking at the licensing guide, MIT/Apache seem to be options? What do I miss?
Well I am apparently hallucinating (see, it's not just LLMs!)
I don't know where I got that in my head, but I swear that at one point I read through all the codeberg docs and it said they only support copyleft---but clearly I am mistaken. Sorry 'bout that!
If you are hallucinating, then we jointly had a similar hallucination, and I don't think we've ever met. I don't think they were so much "copyleft only" as "copyleft strongly encouraged." Some of their updates have clarified that, but private repositories are still not something they're really interested in hosting. (IIRC they allow them in support of FOSS projects, e.g. for internal discussions or upcoming changes that can't yet be public for some reason, and for personal notes, but not really for developing private software.)
I like sr.ht, but if I wanted private forgejo without self-hosting, I'd probably look at pikapods first. That's one of the applications they'll do managed hosting for, priced modestly, and it's the same people behind BorgBase. And if you want people who still use github to collaborate with you, the forgejo "sign in with github" option is pretty low friction.
It's okay, things might have changed, things might have been unclear. Thanks for clearing the situation 😊
Lots of great points and historical perspective. I too feel GH has been a great "commons" for learning and OSS maintenance.
[..] what I would like to see is some public, boring, well-funded archive for Open Source software. Something with the power of an endowment or public funding to keep it afloat. Something whose job is not to win the developer productivity market but just to make sure that the most important things we create do not disappear. The bells and whistles can be someone else’s problem, but source archives, release artifacts, metadata, and enough project context to understand what happened should be preserved somewhere that is not tied to the business model or leadership mood of a single company.
archive
It would be good to see more people talk about Software Heritage and ways to use & support it more. For example here is Flask on there:
I think issues are an important part of the history that are not preserved at the moment. But perhaps Wayback Machine is a better source for that information?
I'd wonder where the boundary is. Should mailing lists be preserved as well? Chat logs? Websites? Youtube release videos?
But sticking to issues: swheritage keeps everything in a git-ish format internally (not sure how much their platform deviates from that, but basically code in other version control systems ought to be converted for import). There are multiple proposals out there how to keep issues in a repo (e.g. git-bug, but there are many others). I suppose once/if that settles to some official format, they could just run the importers?
Many of these choices depend on whether you consider the preserved software to be "done" or not. Nowadays we tend to never consider it done, and dependency treadmill compounds this effect.
There was no data loss: all commits remained stored in Git. However, the state of affected default branches was incorrect, and we could not safely repair every repository automatically. More details are available in the incident root cause analysis.
This is quite a novel use of the phrase "data loss." By this interpretation, there is never any possible data loss in any binary system--your zeros and ones are all there! just maybe not in the right places.
It's an interesting take: to pour petrol on a fire, then apologize to the burning village because your own house got burned down too.
It is high time. I left them long before AI came along and it feels still right, that my code repo isn't owned by a billionaire. Embarrassing enough, that many well meaning require an account there for collaboration with them. So be it then.
If you can, do mirrors and embrace diverse hosting: https://blog.mro.name/2024/10/scaling-infrastructure/#github-com
it's hard to part but needs to be when your honey becomes a bully. Do it for you.
Embrace diverse hosting, do POSSE: https://blog.mro.name/2024/10/scaling-infrastructure/#github-com
Your reaction to the Arctic Code Vault project is pretty interesting to me. I actually found that an exciting and energizing project. Did you read about what the project actually was?
Do you object to the Software Heritage archive? If not, what makes them different? (Not an attack, I'm genuinely curious.)
No i didn't read. They came to me unasked for and put their badge on my profile without asking or saying hello. That's disgusting. There's no respect in it. In hindsight this was but a precursor for AI stealing everything. Neither do I object the Software Heritage archive nor am I familiar with them. It sounds pretentious and self-referential. Few software is worth preserving IMO. Surely not mine. It's open source, do what you please but don't expect applause. And respect the GPL.
I am really missing an atproto type of feature to allow users from GitHub/codeberg to create pull request in my personal public Forgejo instance. That would be the future for me. Also European Union kind of requires that for other services, they could require it for git forges. Anyway Forgejo does the job pretty well.
There is ForgeFed since before ATProto. But email is already federated; DMing the maintainer for a pull request on a federated chat protocol is also fedarate communication; the overreliance on web UIs is the part getting in the way.
Which Microslop product is next on the faux-apology blog post tour? Make your bets!
https://blogs.windows.com/windows-insider/2026/03/20/our-commitment-to-windows-quality/
I think something that looks radically similar to Github like Forgejo is probably going to be it as much as I think that it's a lost opportunity. You have to realize how little the average engineer cares about vcs and how shallow their understanding of git and the forge they use is.
The biggest win that Github has is the institutional entrenchment both in companies and in the hearts and minds of developers. Moving to something else will need that other thing to be radically better (while still hitting more or less feature parity) or for Github to go down under 50% availability. Even then most companies will probably move to Gitlab (which I've seen work at medium scale).
There is also a before Git (& after too!). If moving off MS GitHub for a new project, maybe consider trying a different VCS entirely.
Did you get some spam or not at all? Spammers could use their own domain to login. Dunno, if it's a target interesting enough for them.
{kind=link}
{kind=link}