krabby: making a fast Rust compiler
39 points by aw1621107
39 points by aw1621107
To call this a massive project would be an understatement. I don’t know how likely I am to finish it.
Rust is big. This project sounds slightly easier than "write your own web browser", but that's not saying much. Still, I commend the author for their ambition!
From krabby: motivations, it sounds like speed is the primary reason for the project.
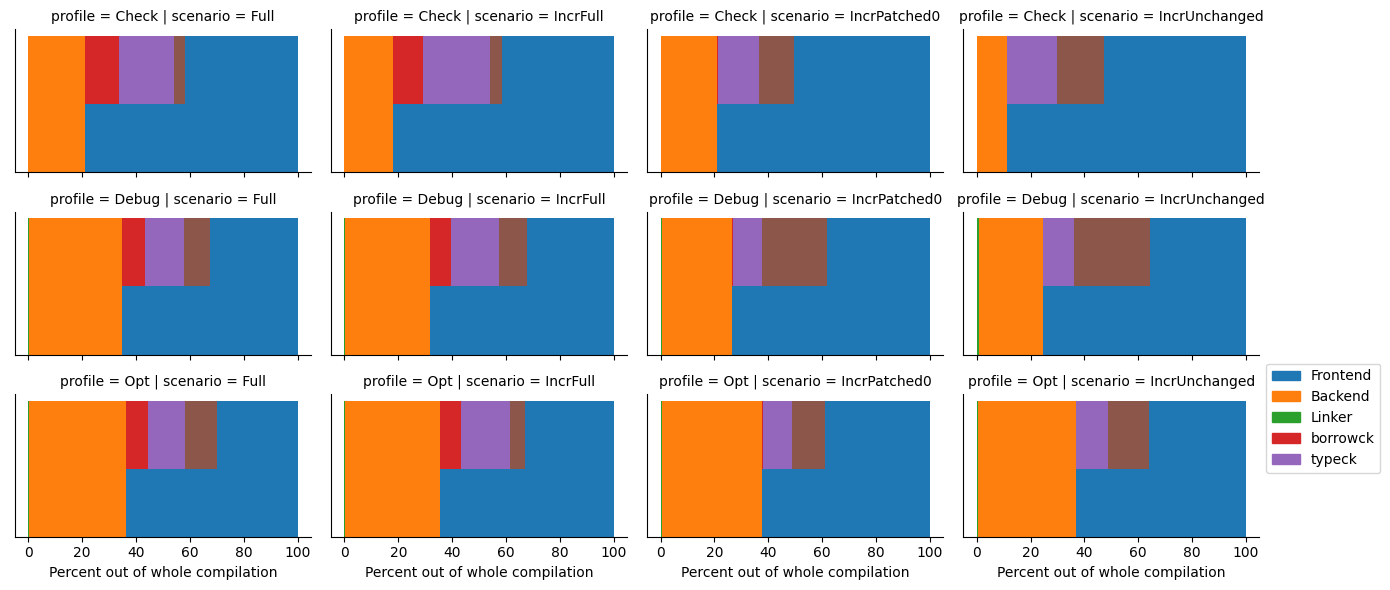
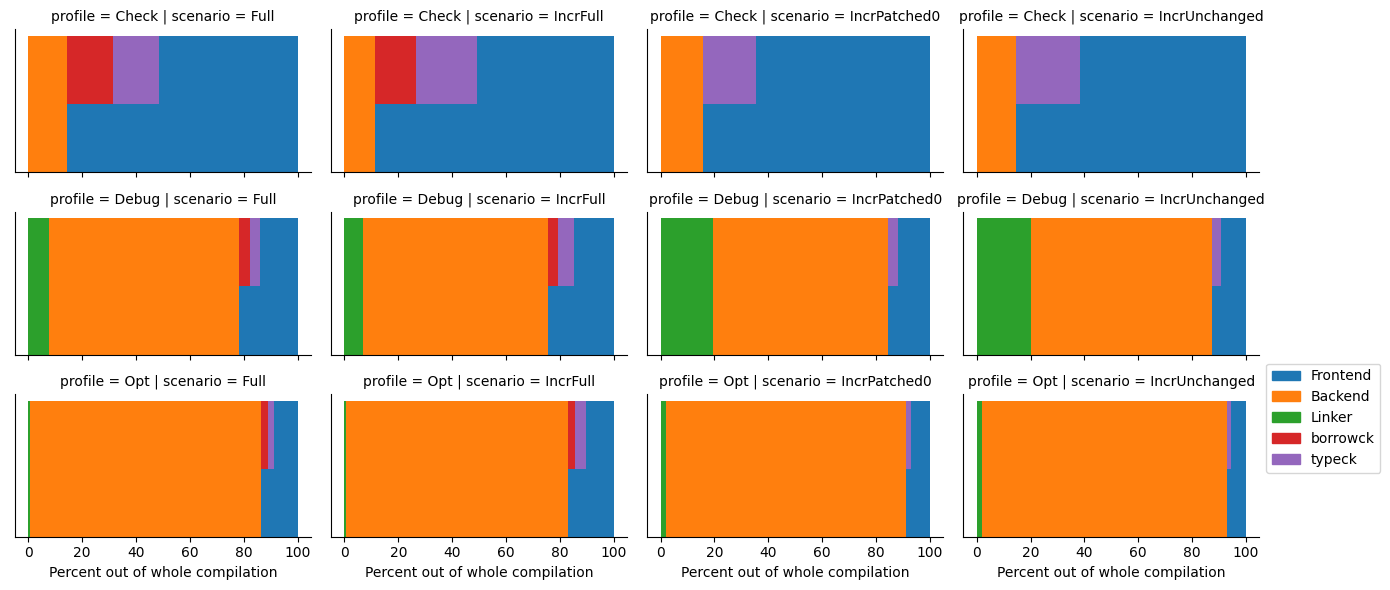
There are two hard cores that we had to consider how to optimize: type-checking (including inference and trait solving) and code generation. We actually have some really interesting ideas for the former (that may even apply to the latter in the future)
My understanding of Rust is that type-checking, borrow-checking, etc, are all very fast already. But code generation is the bottleneck, and a lot of that has to do with LLVM and not Rust itself (for the most part). I wonder what's going on in the Cranelift world these days, and if there's any overlap in ideas for speeding up codegen.
My understanding of Rust is that type-checking, borrow-checking, etc, are all very fast already. But code generation is the bottleneck, and a lot of that has to do with LLVM and not Rust itself
Importantly, this pre-supposes that the overall architecture of rustc+LLVM is right, and only constant factors matter.
But I personally am fairly convinced that the compilation pipeline, viewed holistically, just doesn't make sense. We need MIR-only rlibs, and we need a backend that can do whole-world with optimizations without needing infinite RAM (see this comment). "Codegen Unit" is pure accidental complexity.
My understanding of Rust is that type-checking, borrow-checking, etc, are all very fast already. But code generation is the bottleneck
Depends on what exactly you're doing. Of particular interest might be the specific breakdown for libraries and binaries.
and a lot of that has to do with LLVM and not Rust itself (for the most part).
IIRC it's a bit of column A and a bit of column B. LLVM isn't exactly a speed demon, but it doesn't help that rustc tends (tended? It's been a while) to pass somewhat bloated IR to LLVM.
Thanks :) I think different people have quite different perspectives on Rust compilation times; I hear some people blaming type-checking and others blaming LLVM. My goal for the medium term (the next ~5 years) is cargo check, so I'm not touching on code generation. I still think there's a lot of optimization potential here, between better parallelism, moving (more) diagnostics code off hot paths, reducing duplicate work (between type-checking and borrow-checking), and improving memory layouts for core data structures. It helps that I'm friends with a bunch of rustc devs so I hear about a lot of the problems with the codebase.
I wonder what's going on in the Cranelift world these days, and if there's any overlap in ideas for speeding up codegen.
rustc has a Cranelift backend.
Aye and IIRC while it makes things faster, it’s not “and now it’s like compiling Go”-faster, so there must be some fair amount of overhead in the stack beyond LLVM
LLVM indeed does seem to be the slow part. This is what I have seen from discussions about Zig compile times, their selfhosted counterpart is significantly faster than LLVM1.
everybody got to have their own vanity license https://codeberg.org/bal-e/krabby/src/commit/a8dbf1176d1676465a71184d1198f39a8fb434ad/LICENSE.md#keypunch-public-license-1-0-1
Oh no! For a hobby project I guess it's okay, but it does mean this project is more casual than serious.
This license allows you to use and share this software for personal and NonCommercial purposes for free, but you have to share software that builds on it alike. For commercial purposes you may only try this software for thirty days.
Does Codeberg have any requirements that project licenses be strictly libre/open-source? I was surprised to see a no-commercial-use restriction because I was under the impression that Codeberg only hosts FOSS stuff—but I confess to being a bit behind the curve on this.
Yes it does: https://codeberg.org/Codeberg/org/src/branch/main/TermsOfUse.md#2-allowed-content-usage
Public repository content shall be made available under a copyright licence which gives all natural and legal persons the following rights in the content:
- the right to use the content for any purpose, including both commercial and non-commercial purposes;
It seems like this project's license goes against the terms of use.
But Codeberg’s ToU also state:
works (…) which embody the unique personal creative spirit of the author, may be included in public repositories under a copyright licence which does not allow modification and/or commercial use
IANAL but the phrasing:
works which primarily describe the personal opinions or experiences of the author, or which embody the unique personal creative spirit of the author
to me sounds carved out to allow personal blogs/websites, given Codeberg Pages requires the website content to be on a public repo hosted by them. I don't think it's meant to apply to regular code projects like this.
Not only. I was part of those discussions ever so slightly with an example of a Māori text database made by Māori people that did not want to make their database and associated liberally licensed because they wanted to keep the little control that they had. (This is a concrete project)
Capturing that complexity makes a lot of sense. Codeberg can serve such projects without compromising their mission.
That's a very interesting example, thanks for sharing.
Capturing that complexity makes a lot of sense. Codeberg can serve such projects without compromising their mission.
I agree!
I would argue a "this license is non-commercial with an exception to pay the author after 30 days" does not fall under that category. The reason for those exceptions are complex social situations/power structures.
Hey! Yeah, I know... I've struggled with license stuff a lot. I'm considering changing it to AGPL while it's still me.
Pay no mind to people with no skin in the game and every incentive to bully you into participating in your own exploitation - they'll just turn around and say "well akshully if you don't want to be exploited you shouldn't have picked an open source license" if you're ever in a situation where you need medical care you can't afford or aren't able to make rent.
It's perfectly normal to want to distinguish individuals from corporations, and personal use from corporate use, and for you to have a license that reflects that.
Feel free to hit me up as someone who has successfully navigated the post-open source landscape and found something which works for me at a non-trivial scale.
It's perfectly normal to want to distinguish individuals from corporations, and personal use from corporate use, and for you to have a license that reflects that.
Hard agree.
It might mean you need to use a forge other than codeberg, though, as they generally consider their mission very tied to hosting FOSS. I don't think your license or the one this compiler is offered under really fit with the letter or the spirit of their requirements.
I like what you've done with komorebi in terms of making it sustainable for you. It's on my list of things I think I'd like to try, too, but so far all I've had time to do is admire (from afar) your work on turning it into a business.
Just to be clear as someone who took part in the licensing branch of the discussion above: I'm very fine with any licensing terms someone sets out, it's quite literally their thing and personally hold the stance that open sourcing is a strategic move that one should think hard about the repercussions of.
My only point was that it's in opposition to the stated values of the forge it is hosted on, which explicitly builds itself around that. FWIW, Codebergs hardliner stance there is one of the reasons I'm staying away from it most of the time.
If you're going to have a "post-open source" license, it should be understandable and enforceable then. Just winging one doesn't seem like a good idea.
Just winging one doesn't seem like a good idea
Evidently for a growing number of people, this seems like a better idea than blindly defaulting to corporate-friendly software licensing
There's a reason Bruce Perens calls these "crayon licenses" and Rick Moen calls them "cargo-cult law" in his commentary on the Unlicense's internal inconsistency.)
It's the legal jargon equivalent of relying on the common-English interpretation of words like print() in the context of a programming language... you're gonna get burned when it doesn't refer specifically to hard copy.
A copyright or contract lawyer's job in crafting a new license is essentially to understand the hundreds of years of case law which refine and clarify the implications of common English terms that contract disputes and court cases found to be ambiguous in practice, so they can know exactly which phrasing is closest to what their lay-person client intends... essentially, a professional translator... just English-legalese(jurisdiction) instead of English-French or what have you.
(And for roughly the same reason. print() originally did refer to hard copy, but then it was determined that the value of "glass TTYs" outweighed the value of keeping the function's name literally accurate. Something like output() or reply() probably would have been better, but that's hindsight for you. Similar trade-offs are made in law. Rinse, lather, repeat for centuries.)
Another good example would be this analysis of the CC0, which demonstrates some of the ways German law works that are surprising to people used to the American licensing environment. (eg. It has no provision for putting things into the public domain early. That's an artifact of the U.K. legal system, and it has that EU thing where there are various rights that the original rightsholder can't give up... only make a legally binding promise not to exercise.)
That's also why, if you're doing anything more likely to draw legal attention than writing fanfiction or drawing fanart (including choosing dependencies for software you expect others to take more seriously than that), you're probably going to ignore anything that's under a crayon license. (Hell, fan projects like Them's Fightin' Herds (in its original Fighting is Magic form), Super Mario Bros. X, AM2R, Pokémon Uranium, Axanar, etc. drew more legal attention than writing fanfiction or drawing fanart.)
Heck, it's one reason that I haven't ruled out possible futures where A.I. image generators are treated like ROMs (of the game emulation kind) and people generate porn and fanart using torrented copies of the various Stable Diffusion models.
I am all for license standardization, written by people who know what they're doing. I 100% agree that if you want to block commercial use, there are much better options than winging it in a language you don't understand.
…and at the same time, I'm also happy that folks winging it gave us this moment (transcript).
if you want to block commercial use, there are much better options than winging it in a language you don't understand
A bespoke license is amongst the easiest of ways to prevent commercial use - corporate legal teams default to auto-rejecting anything that isn't on an explicit allowlist.
written by people who know what they're doing
PolyForm has filled this area very nicely, and for anyone keeping track, it's not at all surprising to see more and more post-open source licenses are subtle forks of a PolyForm variant.
The PolyForm Project is a group of experienced licensing lawyers and technologists developing simple, standardized, plain-language software source code licenses.
This is pretty much my point. I'm not saying don't do it. I'm saying standardize on something good.
A bespoke license is amongst the easiest of ways to prevent commercial use - corporate legal teams default to auto-rejecting anything that isn't on an explicit allowlist.
A lot of hobbyists act the same way to hedge their bets against others taking one look at the bespoke license in their dependency tree and nope-ing out.
I know I do.
Just to note, AGPL doesn't just mean corporations are allergic to it, it also means individual employees at a bunch of companies will be disallowed from even personal use of the software on a work computer. Unless you genuinely think that the software is liable to be used by companies on the server side without distributing it in any way to customers, GPL can accomplish the same aims without causing individual employees from being allowed personal use of the software.
a bunch of companies
A bunch of companies, or just the surveillance advertising cartel + a few arms dealers? I'd personally be fine excluding employees of these companies.
My employer does not match that description (regardless of the definitions you use) and forbids AGPL. My understanding as well is that is there are a number of general tech companies that have similar anti-AGPL policies.
it also means individual employees at a bunch of companies will be disallowed from even personal use of the software on a work computer
This is the first time I've seen this about the AGPL. What does it do differently from the GPL that adds this restriction?
As far as I know in terms of legality there is no reason for companies to do this, but it is also a true fact about the world that some companies have irrational fear of AGPL.
I'm not entirely sure, AFAIK the only difference between AGPL and GPL is that AGPL requires that covered software that is accessed over a network offer a "download source" option, but my employer forbids AGPL while merely discouraging GPL3, and my understanding is that my employer is not unique in their behavior here.
{kind=link}
{kind=link}